
Unlocking the Power of Customer Lifetime Value: 5 Key Benefits for Your Business
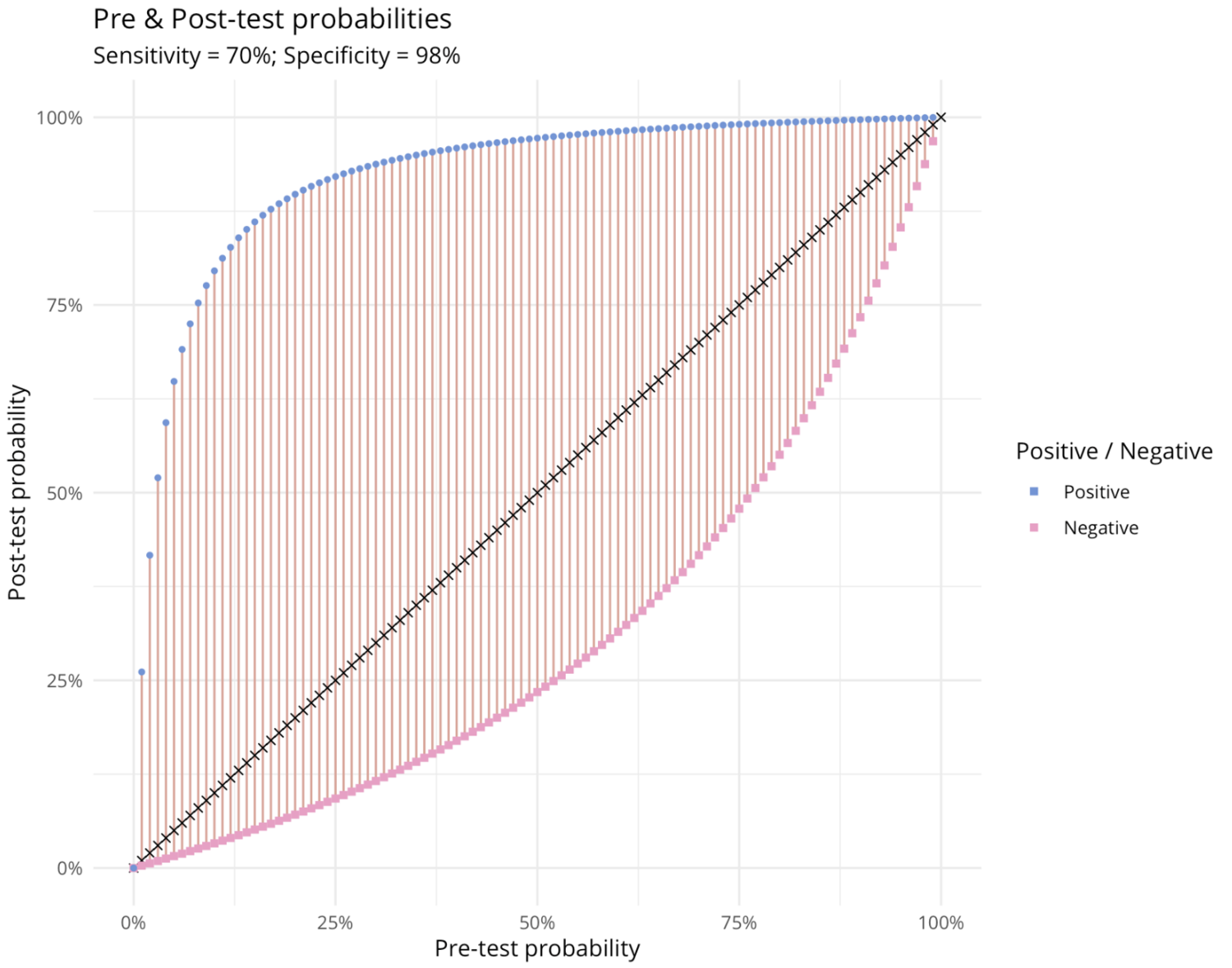
Accurately measuring customer lifetime value allows companies to grow profitably by acquiring higher value, committed customers at a lower cost; by ensuring the profitable ones stay customers for as long as possible; and by developing your relationship with them to ensure they engage with your brand as much as possible.

5 pillars of good marketing measurement
The resurgence of interest in MMM presents an opportunity to shake up marketing science, organising measurement around the critical decisions marketers face.
But many providers are burrowing deeper into existing rabbit holes - spending huge amounts of time and money building overly complex, granular models, which produce results that ultimately have a limited impact on decision making.
A better approach is to focus analytics to where it can have the most impact and to organise measurement around business-critical decisions.
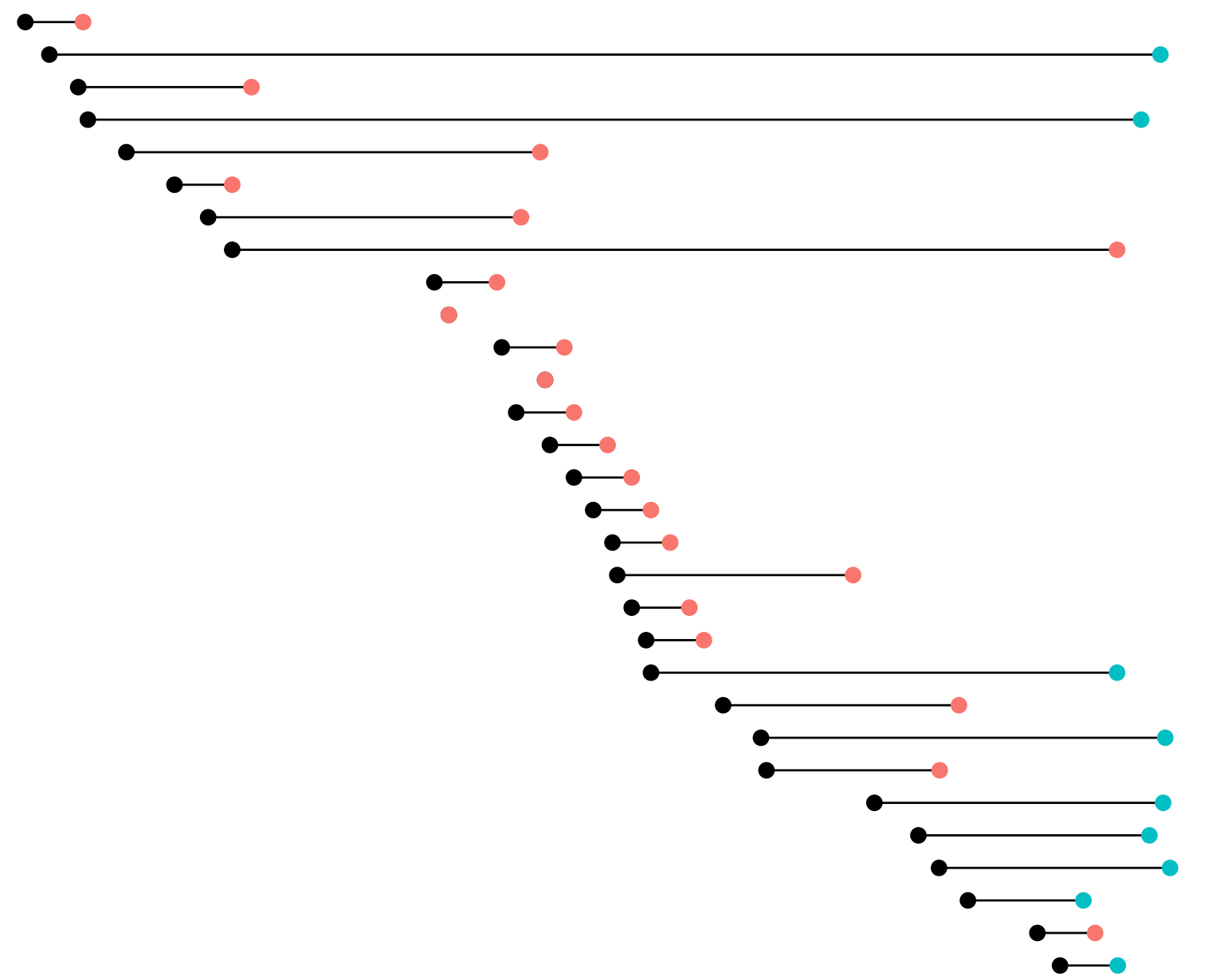
Predicting subscriber lifetime value using survival analysis
How to predict subscriber retention and estimate lifetime value
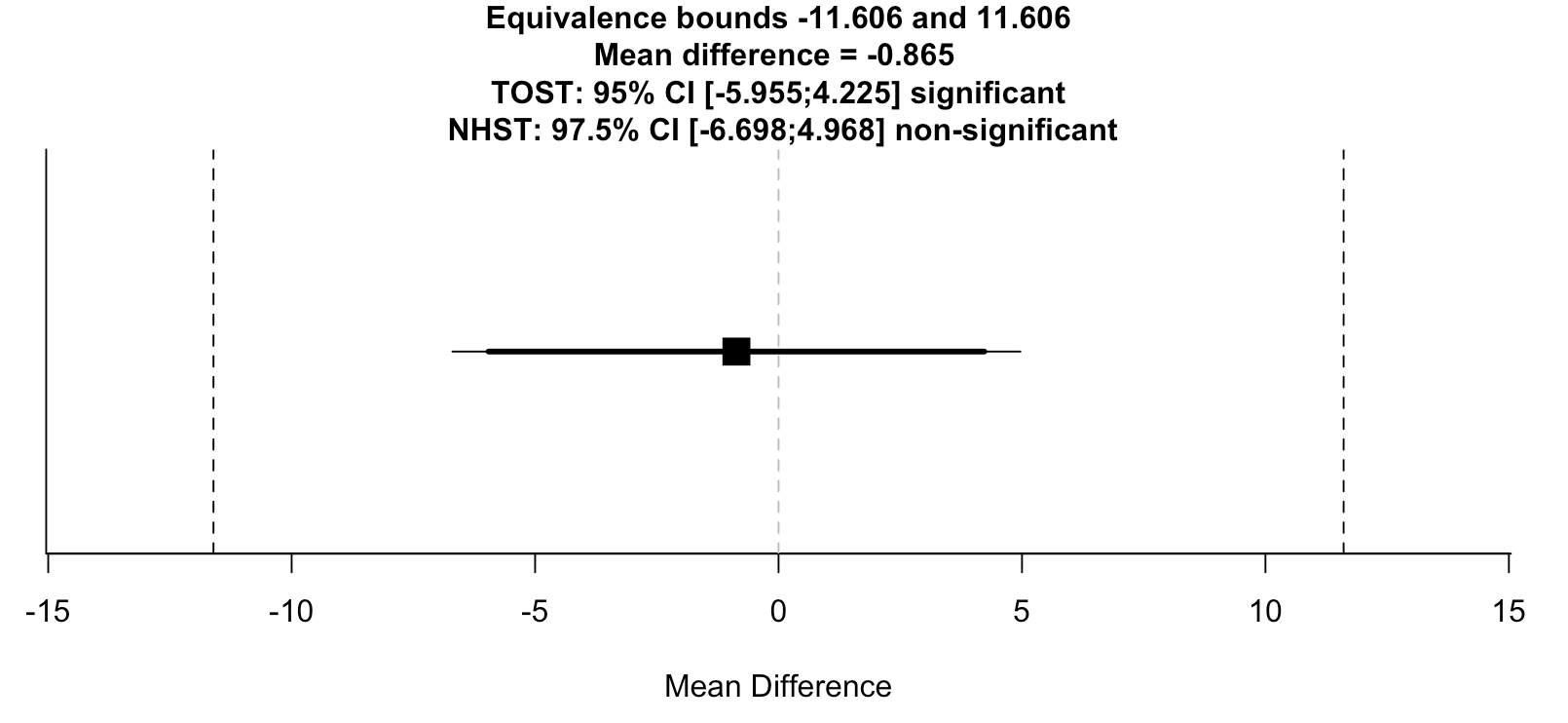
New publication looking at the impact of point-of-care genotyping on routine clinical practice
We collaborated with researchers at the Manchester Centre for Genomic Medicine on a paper looking at the impact of introducing point-of-care genotyping on routine clinical practice.

Is data science becoming a market for lemons?
Is data science becoming a market for lemons?